
Generator of cost-effective GMO testing strategies
Description
GMOtrack is a command line utility that implements the
GMOtrack algorithm. It generates cost-effective testing strategies for
traceability of genetically modified organisms (GMO). Given a table of
GMOs (along with the probabilities of their presence, the genetic
elements present in their genome and a linear cost function) GMOtrack
computes the optimal set of screening assays for a two-phase testing
strategy.
GMOtrack is distributed free under GPL and can be downloaded from this
web page.
Publications
Kralj Novak P., Gruden K., Morisset D., Lavracč., Šebih D., Rotter A., Žel J.
GMOtrack: generator of cost-effective GMO testing strategies
Journal of AOAC International 2009, Nov-Dec;92(6):1739-1746
[pdf],
supplementary material [pdf],
[bib]
Download
Windows executable: GMOtrack.zip
Download data here: [data]
Real-time PCR analysis costs: PCRcosts.pdf
is a document with the cost schema
For developers: Python source code GMOtrack-sources.zip
which is developed with Orange
version 0.9.64.
Installation
Unzip the file GMOtrack.zip. GMOtrack is a command-line utility so run it from the command line as described below. To start the command line, you can use the run.bat script, which is enclosed in the GMOtrack.zip archive.
Usage
GMOtrack is a command-line utility. GMOtrack usage:
GMOtrack filename [-m int][-c float][-k float][-n float]
- -mmaximum assays for first phase constraint, default m=5
- -cminimum coverage (in %) of the first phase, default c=80
- -kcoefficient for the cost function g, default k=21.18
- -nconstant for the cost function g, default n=91.82
The program returns for each number i up to m the combination of i screening assays with the lowest expected total cost.
Sample output
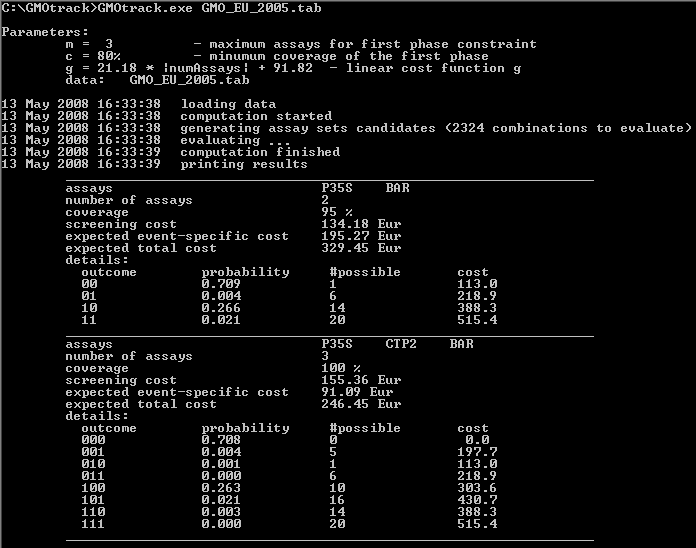
Data
We have prepared the sample datasets.
They were used for the experiments in the paper.
| dataset | year | frequency | # GMOs | # screening assays |
| GMO_EU_1997.tab | 1997 | all | 7 | 18 |
| GMO_EU_1999.tab | 1999 | all | 15 | 22 |
| GMO_EU_2002.tab | 2002 | all | 17 | 24 |
| GMO_EU_2005.tab | 2005 | all | 20 | 24 |
| GMO_EU_2008.tab | 2008 | all | 22 | 25 |
| GMO_EU_2008-food.tab | 2008 | food | 22 | 25 |
| GMO_EU_2008-feed.tab | 2008 | feed | 22 | 25 |
| GMO_EU_beyond2008.tab |
beyond 2008 | all | 37 | 32 |
Here we describe how you can prepare your own data to be used with GMOtrack.
We recommend to take one of the available datasets (above) and modify it in a
spreadsheet program (e.g. MS Excel). Be careful when saving, since the file must be a
"Tab delimited" text file and the filename must end with ".tab".

GMOtrack uses the ".tab"
data format with some additional specifics.
The data must be in a tab separated text file with following format:
- File head:
- The first line is reserved for column names: meta
attribute names and assay names.
- the first three columns must be named "GMOname", "species" and "probability".
- The second line denotes the data type:
- d for nominal values
- c for numbers
- The third line denotes column type:
- m for meta attributes (GMOname, species and probability)
- empty for assays
- The first line is reserved for column names: meta
attribute names and assay names.
- File body:
- Each line is the file's body is one GMO.
The first column represents GMO names.
The second column must be species.
The following columns are the responses of the GMO to the assay:
- 1 means positive response,
- 0 means negative response.
- Each line is the file's body is one GMO.
Example input data

Funding
Funding was provided by the Slovenian Research Agency (P4-0165, P2-0103); the Slovenian Ministry of Agriculture, Forestry and Food; and the Slovenian Ministry of the Environment and Spatial Planning (V4-0314).